字符串替换多个字符,并且替换中的字符不影响下一次替换。 2019-12-16 08:45:37 - 2025-08-18 00:12:03 無慕 - 73 - 0秒 - 2.26K 例如:把<替换成<>,把>替换成><,不管谁在前都会影响下一次。let newStr= oldStr.replace(/<|"|=|\/|>/g, str => { let return_str = str; switch (str) { case "<": return_str = `<>`; case ">": return_str = `><`; break; } return return_str; }); 编程 - 前端 JavaScript 问题
Linux常用命令 2019-09-26 16:47:00 - 2025-08-18 00:12:03 無慕 - 2.85K - 18.27分钟 - 2.58K 目录操作进入dir目录cd dir返回上一级cd ..返回上两级cd ../..返回根目录cd /返回最近一次访问目录cd -查看当前访问路径pwd将test目录或文件压缩成一个名为newzip的压缩文件,可在名称前加上路径zip newzip.zip test查看当前目录内容ls查看目录中的隐藏文件ls -a创建名为dir的目录mkdir dir删除名为dir的目录或文件rm -rf dir移动dir目录到指定url路径mv dir url复制dir目录下所有内容到dir2目录中,其中dir和dir2都可以是目录所在路径。备注:如果复制目录则必须需要加-r参数,才能将目录中的所有内容都复制过去,复制文件则不需要加-r参数。cp -r dir dir2查看当前目录下所有目录或者文件的大小(但不包括目录下的大小)和权限信息。单位:B,以下两种相同ls -llls -l单位:KBls -lh查看当前所在目录权限以及大小(但不包括目录下的大小),加h单位是KB,不加则为B。ls -ld查看当前所有目录和文件的总大小(包括目录下面内容的大小),单位自动,视情况使用KB、MB、GB等。du -sh查看名为dir的目录或文件大小(包括目录下面内容的大小),单位自动,视情况使用KB、MB、GB等。du -sh dir查看当前目录下所有一级目录或文件各自的大小--max-depth指定最大深度,0就是只计算查看当前目录下的内容。如果想查询到当前目录的二级子目录,则可以将0改为1,三级子目录则改为2,以此类推……du -h --max-depth=0 *如果是1,则会把这几个目录下的二级子目录和文件都计算展示出来。文件编辑查看file文件内容,正向查看文件。cat file查看file文件内容,反向查看文件。tac file打开一个file文件vim file打开文件后编辑文件I使用I进入编辑模式后退出编辑ESC按ESC退出编辑后使用,保存并退出编辑窗口:wq按ESC退出编辑后使用,保存但不退出编辑窗口:w按ESC退出编辑后使用,强制性保存但不退出编辑窗口:w!按ESC退出编辑后使用,将修改保存到另外的file中,当file文件不存在时自动创建:w file按ESC退出编辑后使用,强制性保存并退出编辑窗口:wq!按ESC退出编辑后使用,不保存退出并退出编辑窗口:q按ESC退出编辑后使用,不保存强制退出并退出编辑窗口:q!按ESC退出编辑后使用,放弃所有修改,从上次保存的开始编辑::e!权限相关查看当前目录下的权限信息备注:文件最前方有十个字符。第一个代表文件类型,-代表是普通文件,d代表是目录。后面九个代表权限一共分成3组,每3个一组,分别是所有者、所属组、其他人。ls -l给dir目录或文件设置777权限。权限数字表示:r=4,w=2,x=1。例如:rwxrw-r--:三个一组,rwx权限分别对应421,相加得7,rw-对应42相加,r--对应4。chmod 777 dir给dir目录以及他下面文件和目录设置777权限,R必须大写。chmod -R 777 dir给dir目录或文件的所有者单独加一个读的权限u:所有者, g:所属组,o:其他人,a:所有。+:添加权限,-减少权限,=直接赋值成这个权限。chmod u+r dir其他命令查看80端口占用情况lsof -i tcp:80netstat 命令用于显示网络状态#查看TCP和Socket的网络信息,并显示正在使用Socket的程序识别码(pid)和程序名称 netstat --tcp --listening --program #等同于:netstat -t -l -pkill 命令用于杀死指定pid的进程(假设Websocket进程的pid为123456)kill 123456 #杀死进程 kill -KILL 123456 #强制杀死进程 kill -9 123456 #彻底杀死进程(是操作系统从内核级别强制杀死一个进程) kill -15 123456 可以理解为操作系统发送一个通知告诉应用主动关闭.拼合命令:杀死指定(9502)端口进程kill -15 `netstat -nlp | grep :9502 | awk '{print $7}' | grep -o '[0-9]*'`持久化启动python3的Django项目nohup python3 manage.py runserver 0.0.0.0:80 >>log_app.out>&1 &持久化启动某个程序,log_app.out 为日志文件,&1是保存标准输出内容的意思,最后&后台运行的意思nohup 启动命令 >>log_app.out>&1 &根据 文件或目录名称 搜索find 【搜索目录】【-name或者-iname】【搜索字符】:-name和-iname的区别一个区分大小写,一个不区分大小写eg:在/etc 目录下搜索名字为init的文件或目录find /etc -name init (精准搜索,名字必须为 init 才能搜索的到) find /etc -iname init (精准搜索,名字必须为 init或者有字母大写也能搜索的到) find /etc -name *init (模糊搜索,以 init 结尾的文件或目录名) find /etc -name init??? (模糊搜索,? 表示单个字符,即搜索到 init___) 编程 - 服务器 Linux CentOS 命令行
MySQL相关知识 2019-08-31 08:24:28 - 2025-08-18 00:12:03 無慕 - 646 - 19秒 - 2.41K 相关命令mysqladmin --version 验证mysqlmysql -h主机地址 -u用户名 -p 连接mysqlshow engines 查看数据库支持的引擎show variables like '%storage_engine%' 查看当前使用的数据库引擎其他知识MySQL数据库中*.opt和*.frm和*.myi和*.myd文件是什么文件?作用是?MySQL每个数据库都会在data目录下生成一个目录,里面有*.frm、*.myi、*.myd和*.opt文件。*.frm--表定义,是描述表结构的文件。*.MYD--"D"数据信息文件,是表的数据文件。*.MYI--"I"索引信息文件,是表数据文件中任何索引的数据树。*.opt--记录数据库选项,数据库的字符集。MySQL数据库增删改查的返回值是什么?增:返回添加记录的id,删和修返回影响的条数,查返回查询出来的结果集。MySQL数据库版本:5.X:5.0-5.1:早期产品的延续,升级维护5.2-5.3:不常用5.4-5.X:MySQL整合了三方公司的新存储引擎,以前的版本都是mysql自己单干。(现在主要是用5.5和5.7)MySQL数据库原理连接层:提供与客户端连接的服务服务层:1.提供各种接口。2.提供SQL优化器:MySQL QUery Optimizer引擎层:提供了各种存储数据的方式(InnoDB MyISAM)存储层:存储数据MySQL数据库引擎InnoDb:事务有限,适合高并发操作;行锁MyISAM:性能优先 编程 - 数据库 问题 MySQL 笔记
谷歌插件推荐 2019-08-17 08:55:28 - 2025-08-18 00:12:03 無慕 - 275 - 36秒 - 2.75K 插件篇FeHelper(前端助手)内置很多实用工具,例如:josn美化、时间戳转化工具、思维导图、网页性能检测、二维码生成/解码、代码压缩工具、MArkdown工具、页面取色工具、简易postman…………Charset可以改变页面的编码格式。广告净化器可以根据具体网站和对应的元素进行屏蔽,可以选择任意元素进行屏蔽,不仅限于广告。喵喵折可以查看各大网商的历史价格变化曲线,自动生成在商品详情页上,鼠标移动上去自动显示。Video speed buttons可以通过s(减小)和d(增加)页面视频的播放速度,实测后发现包括一些学习视频,不能快进的也可以! 编程 - 编程软件 插件 浏览器
PhpStorm插件推荐 2019-08-17 08:39:28 - 2025-08-18 00:12:03 無慕 - 184 - 1.03分钟 - 2.57K 插件篇GitToolBox理由:可以跟踪每行代码的git提交修改记录。Translation最好用的翻译软件,选中代码Ctrl+shift+Y翻译代码,Ctrl+shift+O打开翻译器。使用篇//todo的用途由于某些原因,导致部分代码没有写,但又怕忘记,可以以//todo为开始写注释,后期想要查找时,可以使用快捷键alt+6查看项目中那些文件使用了//todo。 编程 - 编程软件 插件 PhpStorm
$.ajax()方法简单整理 2019-07-31 15:44:37 - 2025-08-18 00:12:03 無慕 - 2.54K - 24秒 - 2.25K 前言ajax也分很多种,本人用的最多的是jQuery的Ajax,这篇文章就大概说一下相关的知识点。首先下面是常用的ajax使用方式,其中的参数也是经常用到的:$.ajax({ type:"post/get", url:"url", async:true/fasle, dataType:"json", processData:"true", contentType:"application/x-www-form-urlencoded", data:{ value_name:value }, success:function (data,status,ajaxclass) { //处理返回的数据 }, error:function () { //ajax失败时执行的方法 } })参数说明type:传值类型,分为POST和GET两种,不区分大小写,默认为GET。实际上put、delete等传值方式也能使用,但仅部分浏览器支持。url:发送请求的地址async:是否异步,不写该属性时默认true。(异步是多线程,同步是单线程)设置为true时,所有请求为异步。设置为false时,所有请求未同步。注意,同步请求将锁住浏览器,用户其它操作必须等待请求完成才可以执行。data:发送到请求地址的数据,将自动转换为请求字符串格式。单个值可直接写。例如name,接口可以接受到name这个值。多个值用json格式。{参数名:值,参数名:值,……}的形式,或者直接写变量名{变量1,变量2,变量3,……}。success:当请求运行成功时的回调函数,并返回根据 dataType 参数进行处理后的数据。参数一:data(这里参数名称任意)即为返回的值参数二:status(这里参数名称任意)返回ajax的执行状态,这里返回success参数三:ajaxclass(这里参数名称任意)返回当前ajax对象的一些数据。error:当请求运行失败时的回调函数,一般用作请求地址响应失败时给予用户报错提示。dataType:请求返回后要处理成的数据类型。常用值:"xml": 返回 XML 文档,可用 jQuery 处理。"html": 返回纯文本 HTML 信息;包含的 script 标签会在插入 dom 时执行。"script": 返回纯文本 JavaScript 代码。不会自动缓存结果。除非设置了 "cache" 参数。注意:在远程请求时(不在同一个域下),所有 POST 请求都将转为 GET 请求。(因为将使用 DOM 的 script标签来加载)"json": 返回 JSON 数据 。"jsonp": JSONP 格式。使用 JSONP 形式调用函数时,如 "myurl?callback=?" jQuery 将自动替换 ? 为正确的函数名,以执行回调函数。"text": 返回纯文本字符串processData:参数值为true或false,默认为true一般情况下,通过data选项传递进来的数据,如果是一个对象(技术上讲只要不是一个字符串),都会处理转化成一个查询字符串,以配合默认内容类型“application/x-www-form-urlencoded”。如果发送DOM树信息或其他不希望转换的信息,则需要设置为false。此属性在使用FormData进行data传值时属性值必须为falsecontentType:默认值“application/x-www-form-urlencoded”,是发送信息至请求地址时内容编码类型。此属性在使用FormData进行data传值时属性值必须为false。end,waiting for update……其他说明contentType在传输文件时为什么设为false?相关知识扩充:①如果不加此参数,会出现不可预知的错误!比如某些加了安全控件的系统,不加此参数,会直接报错403,服务器认为你的此次请求是在攻击系统。②当ajax上传文件时,我们查看Request headers:这时会发现content-Type这个的参数是multipart/form-data后面还会有boundary再接着一串随机字符串。前面的参数我们并不陌生,这是form表单上传文件必须的参数,而后面的参数是当我们上传文件时,系统会自动生成一堆随机字符串,也叫分界符,目的是为了防止文件中出现分隔符导,最终致请求地址的服务器无法正确解析文件的起始位置。换言之就是,文件传输中本质还是文件流传输(其实也就是字符代码的传输),这样就需要与其他非文件参数进行区分,而boundary生成的这个复杂随机字符串就是为了将文件流与其他参数区分开来,而将contentType设为false是为了防止jQuery对数据进行二次编码,从而失去分界符,最终导致请求地址的服务器无法正常解析文件。processData在传输文件时为什么设为false?按默认值也就是true,会将上传的数据转换为字符上传,而当上传文件的时候,则不需要把其转换为字符串,因此就要关闭此转换功能,也就是设置为false。 编程 - 前端 jQuery Ajax JavaScript
Git笔记 2019-07-18 16:24:01 - 2025-08-18 00:12:03 無慕 - 2.92K - 17秒 - 2.28K Git命令HEAD是一个指针,通常情况下它可以将它与当前分支等同(其实它是指向当前分支)HEAD 表示当前版本,也就是最新的提交。上一个版本就是 HEAD^ ,上上一个版本就是 HEAD^^ ,往上100个版本写100个 “ ^ ” 比较容易数不过来,所以写成 HEAD~100 。HEAD~2 相当于 HEAD^^ 。git实际上分为三个仓库,本地工作区,中间暂存区,远端仓库。提交命令git add .作用:把修改和添加的文件提交到暂存区,但不包括删除的文件。git add -u作用:把修改和删除的文件提交到暂存区,但不包括新文件git add -a作用:提交所有变化撤销操作:当提交代码时不小心添加了错误文件,可以通过git reset HEAD进行撤销上次的全部提交,git reset HEAD ./../index.php 用来撤销某个文件。注释命令git commit -m “message”作用:简要说明提交的改动。查看改动命令git diff作用:查看当前工作区和版本库里最新版本的区别。拉取命令git pull作用:从仓库或者本地的分支拉取并且整合代码。git pull origin master作用:拉取远程分支并且整合代码。合并出现问题时可以通过git reset --merge进行回退推送命令git push作用:把改动提交到当前分支上查看分支git branch作用:查看所有本地分支git branch -r作用:查看所有远程分支git branch -a作用:查看所有分支切换分支git checkout作用:检出(切换)分支git fetch作用:当git branch -a 查看不到新的分支,git fetch更新一下分支信息后就可以看见新分支了。合并分支git merge作用:将其他分支合并到当前分支恢复之前版本git reset HEAD作用:拉取最新一次提交到版本库的文件到暂存区,单独拉取某个文件用git reset HEAD -- index.php,然后git checkout可以拉取暂存区文件到本地仓库,同样的git checkout -- index.php可以从暂存区单独拉取一个文件到本地仓库。git reset --hard 版本号作用:拉取指定版本的文件到暂存区。注意:如果想恢复到之前某个提交的版本,且那个版本之后提交的版本我们都不要了,就可以用这种方法。恢复之前版本git revert -n 版本号注意:创建一个新的版本为之前提交的某个版本,可以先用git log 查看所有提交记录。git revert HEAD~3作用:撤销HEAD指针之前的第3个提交,并且生成一个新的提交。注意:如果我们想撤销之前的某一版本,但是又想保留该目标版本后面的版本,记录下这整个版本变动流程,就可以用这种方法。配置全局和局部的用户名、密码、邮箱局部: git config user.name “用户名” git config user.passsword “密码” git config user.email “邮箱” 全局: git config --global user.name “用户名” git config --global user.passsword “密码” git config --global user.email “邮箱” 查看设置: git config --list有时拉取代码失败可能需要当前克隆仓库的账号密码,使用以下命令:git clone --bare http://username:password@gitlab.300.cn/package1/myProject.git其中:①如果username使用的是邮箱,那么@符号要用%40代替,例如:123@qq.com,要写成123%40qq.com实践问题最近一次commit有问题怎么办(不进行再一次提交修改本次提交)?代码:git add 我是修改内容.text gitcommit --amend解释:【amend】袖中,会对最新一条commit进行修正,会把当前的commit和暂存区的内容合并起来后创建一个新的commit,用这个新的commit把当前commit替换掉刚提交完代码发现,还有没保存的文件,漏提交了上去了怎么办?代码: git add 我是忘提交的文件.text git commit -amend --no-edit解释:他表示提交信息不会更改,在git上仅为一次提交。刚写完的提交太烂了,不想要了直接丢弃怎么办?代码: git reset --hard HEAD^ git pull解释:HEAD表示HEAD^往回数一个位置的commit,HEAD^表示你要恢复到哪个commit。因为你要撤销最新的一个commit(也就是当前未提交的内容),所以你要恢复到它上一次commit,也就是HEAD^。那么使用git reset --hard HEAD^就会恢复到上次提交前的样子,这时候再git pull把最后一次commit拉取下来,这样刚写完的修改就被撤销了(注意:一旦撤销到某个版本,那么这个版本之后的记录会全部消失,例如撤销到倒数第二次提交,那么最后一次提交记录就会彻底消失)。代码已经push到线上,我想撤回到某个版本怎么办?代码: git revert HEAD解释:将代码回退到上一个版本,并生成一个新的提交记录,原历史记录不变。 实际上它commit了一条与上一个版本相反的内容,相互抵消,达到撤销的效果。 编程 - 远程仓库 Git 笔记
Redis秒杀基础 2019-07-18 14:34:28 - 2025-08-18 00:12:03 無慕 - 3.68K - 19秒 - 2.36K 直接储存connect('127.0.0.1', 6379, 30); //设置连接密码 $redis->auth('junyi'); //获取出售的数量,默认为空 $kuchun = $redis->get('kucun'); //秒杀数量 $total = 100; if ($kuchun < $total) { //监控售出数量是否变动,一旦中途变动就会打断redis事务 $redis->watch('kucun'); //开启事务 $redis->multi(); //设置售出数量+1 $redis->set("kucun", $kuchun + 1); //执行事务 $result = $redis->exec(); if ($result) { //剩余数量 $number = $total - ($kuchun + 1); //$openid 用户id $openid = $number; $redis->hset("list", "user_" . $openid, $kuchun); //获取抢购成功的用户 $data = $redis->hgetall('list'); var_dump($data); var_dump($number); } else { var_dump('手气很差哦,再试一下!'); } } else { var_dump('已经被抢光了'); } }先存后取connect('127.0.0.1', 6379); for ($i = 1; $i rPush("goods_list", $i); } } //秒杀 function kill() { //假设这是是用户的uid $uuid = md5(uniqid('user') . time()); //创建连接redis对象 $redis = new \Redis(); //连接到服务器127.0.0.1,端口号6379,默认连接时间300,密码为空 $redis->connect('127.0.0.1', 6379); //监控列表中的值是否变动 $redis->watch("goods_list"); //开启事务 $redis->multi(); //从左边开始删除一个元素,并把删除的值赋给$goodsId if ($goodsId = $redis->lPop("goods_list")) { //秒杀成功,将幸运用户存在集合中 $redis->hSet("buy_order", $uuid, $goodsId); //执行事务 $redis->exec(); } else { //秒杀失败,将失败用户计数,默认从0开始+1 $redis->incr("fail_user_num"); } echo "SUCCESS"; } 编程 - 后端 PHP Redis 笔记
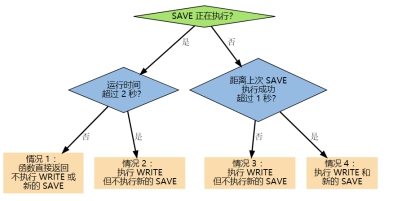
Redis介绍 2019-07-17 09:52:28 - 2025-08-18 00:12:03 無慕 - 5.43K - 26秒 - 1.93K 简介Redis支持数据的持久化,可以将内存中的数据保存的在磁盘中,重启时可以再次加载进行使用Redis不仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的储存。Redis支持数据的备份,即master-slave模式的数据备份优势性能极高-Redis能读的速度是110000次/s,写的速度是81000次/s。丰富的数据类型-Redis支持二进制的案例String,Lists,Hashes,Sets以及Oracle Sets等数据类型操作。院子-Redis的所有操作都是原子性的,意思就是要么成功执行要么失败完全不执行。单个操作是原子性的。多个操作也支持事务,即原子性,通过MULTI和EXEC指令包起来。丰富的特性-Redis还支持publish/subscribe,通知,key过期等等特性。Redis与其他key-value存储有什么不同?Redis有着更为复杂的数据结构并且提供对他们的原子性操作,这是一个不同于其他数据库的进化路径。Redis的数据类型都是基于基本数据结构的同时对程序员透明,无需进行额外的抽象。Redis运行在内存中但是可以持久化到磁盘,所以在对不同数据集进行高速读写时需要权衡内存,因为数据量不能大于硬件内存。在内存数据库方面的另一个优点是,相比在磁盘上相同的复杂的数据结构,在内存中操作起来非常简单,这样Redis可以做很多内部复杂性很强的事情。同时,在磁盘格式方面他们是紧凑的以及追加的方式产生的,因为他们并不需要进行随机访问。无序集合和有序集合Redis的set是string类型的无序集合。集合成员是唯一的,这就意味着集合中不能出现重复的数据。Redis的有序集合和set一样也是string类型的元素集合,且不允许重复的成员。不同的是每个元素都 会关联一个double类型的分数,redis正式通过分数来为集合中的成员进行从小到大的排序。有序集合 的成员是唯一的,但分数却可以重复。Redis事务标记事务的开始:MULTI执行所有事务:EXEC取消事务:DISCARD见识一个或多个key,如果在事务执行前这个(或这些)key被其它命令所改动,那么事务将会被打断WATCH key [key……]注意:单个redis命令的执行是原子性的,但Redis没有在事务上增加任何维持原子性的机制,所以Redis事务的执行并不是原子性的。事务可以理解为一个打包的批量执行的脚本,但批量命令并非原子性的操作,中间某条指令的失败不会导致前面已做的指令的回滚,也不会造成后续的指令不做。RDB和AOF两种持久化方式说明RDB(redis database),可以理解为快照/内存快照,RDB持久化过程是将当前进程中的数据生成快照存储 到硬盘中。AOF(append only file),以日志的方式记录每次写命令,服务重启的时候重新执行AOF文件中的命令 来恢复内存数据。因为解决了数据持久化实时性的问题,所以目前AOF是Redis持久化的主流方式。RDB和AOF两种持久化方式的触发机制都分为两种:手动触发和自动触发。RDB手动触发:执行save和bgsave两个命令可以手动触发RDB持久化。save命令会阻塞当前服务器,直到RDB完成为止,如果数据量大的话会造成长时间的阻塞,线上环境一般禁止使用。bgsave很好理解,就是background save,执行bgsave命令时Redis进程会fork一个子进程来完成RDB的过程,完成后自动结束,所以Redis主进程阻塞时间只有fork阶段的那一下。相对于save,阻塞时间很短。自动触发: 在redis.config配置文件里可以配置自动触发:save <seconds> <changes>,这个配置的规则指的是在seconds秒内发生changes次写操作,就会自动进行一次bgsave,例如:save 900 1,指的是如果900秒内有1条Key信息发生变化就会触发一次bgsave。 还有在执行shutdown命令的时候,如果没有开启AOF持久化功能,那么会自动执行一次bgsave。执行流程:执行bgsave命令的时候,Redis主进程会检查是否有子进程在执行RDB/AOF持久化任务,如果有的话,直接返回。Redis主进程会fork一个子进程来执行执行RDB操作,fork操作会对主进程造成阻塞(影响Redis的读写),fork操作完成后会发消息给主进程,从而不再阻塞主进程。 RDB子进程会根据Redis主进程的内存生成临时的快照文件,RDB完成后会使用临时快照文件替换掉原来的RDB文件。RDB子进程完成RDB持久化后会发消息给主进程,通知RDB持久化完成。RDB优点:RDB文件小,非常适用于定时备份,用于灾难恢复。 Redis加载RDB文件的速度比AOF快很多,因为RDB文件中直接存储的内存数据,而AOF文件中存储的是一条条命令。RDB缺点: RDB无法做到实时持久化,因为fork子进程属于重量级操作,会阻塞Redis主进程。存在老版本的Redis不兼容新版本RDB格式文件的问题。主要因为RDB持久化不支持实时持久化,只要Redis服务宕机了,那么从上一次bgsave到宕机之间的所有数据都会丢失,所以在数据实时性要求高的情况下不适合使用RDB,所以Redis又提供了AOF持久化其他细节性说明:在有子进程执行RDB过程的时候,Redis主进程的读写不受影响,但是对于Redis的写操作不会同步到主进程的主内存中,而是会写到一个临时的内存区域作为一个副本,等到主进程接收到子进程完成RDB过程的消息后再将内存副本中的数据同步到主内存。Redis默认采用LZF算法对RDB文件进行压缩,所以生成的内存文件会比内存小很多。AOF说明:AOF默认是关闭的,可以在redis.conf配置文件中添加下面配置开启AOF:appendonly yes手动触发:执行bgrewriteaof命令直接触发AOF重写。自动触发:在redis.config配置文件中有两个配置项:auto-aof-rewrite-min-size 64MB auto-aof-rewrite-min-percenrage 100上面两个配置表示: - 当AOF文件小于64MB的时候不进行AOF重写 - 当当前AOF文件比上次AOF重写后的文件大100%的时候进行AOF重写可以在redis.conf配置文件中添加这两个参数来自动触发AOF重写,执行bgrewriteaof命令执行流程:所有的写命令都会追加到aof_buf(缓冲区)中。可以使用不同的策略将AOF缓冲区中的命令写到AOF文件中。随着AOF文件的越来越大,会对AOF文件进行重写。当服务器重启的时候,会加载AOF文件并执行AOF文件中的命令用于恢复数据。简单分析一下AOF执行流程中的一些问题:因为Redis为了效率,使用单线程来响应命令,如果每次写命令都追加写硬盘的操作,那么Redis的响应速度还要取决于硬盘的IO效率,显然不现实,所以Redis将写命令先写到AOF缓冲区。写道缓冲区还有一个好处是可以采用不同的策略来实现缓冲区到硬盘的同步,可以让用户自行在安全性和性能方面做出权衡。同步策略:在了解同步策略之前,需要先来了解两个三方法flushAppendOnlyFile、write和save:redis的服务器进程是一个事件循环,文件事件负责处理客户端的命令请求,而时间事件负责执行serverCron函数这样的定时运行的函数。在处理文件事件执行写命令,使得命令被追加到aof_buf中,然后在处理时间事件执行serverCron函数会调用flushAppendOnlyFile函数进行文件的写入和同步write:根据条件,将aof_buf中的缓存写入到AOF文件save:根据条件,调用fsync或fdatasync函数将AOF文件保存到磁盘Redis支持的三种同步策略:AOF_FSYNC_NO:不保存(write和read命令都由主进程执行)AOF_FSYNC_EVERYSEC:每一秒钟保存一次(write由主进程完成,save由子进程完成)AOF_FSYNC_ALWAYS:每执行一个命令保存一次(write和read命令都由主进程执行)AOF_FSYNC_NO:在这种策略下,每次flushAppendOnlyFile函数被调用的时候都会执行一次write方法,但是不会执行 save方法。只有下面三种情况下才会执行save方法:Redis被关闭AOF功能被关闭系统的写缓存被刷新(可能是缓存已经被写满,或者定期保存操作被执行)这三种情况下的save操作都会引起Redis主进程阻塞,并且由于长时间没有执行save命令,所以save 命令执行的时候,阻塞时间会很长。AOF_FSYNC_EVERYSEC:在这种策略下,save操作原则上每隔一秒钟就会执行一次, 因为save操作是由后台子线程调用的, 所 以它不会引起服务器主进程阻塞。其实根据Redis的状态,每当 flushAppendOnlyFile函数被调用时,write命令和save命令的执行又分 为四种不同情况:根据以上图知道,在AOF_FSYNC_EVERYSEC策略下, 如果在情况1时发生故障停机, 那么用户最多 损失小于2秒内所产生的数据;而如果在情况2时发生故障停机,堆积了很多save命令,那么用户损 失的数据是可以超过 2 秒的。AOF_FSYNC_ALWAYS:在这种模式下,每次执行完一个命令后,write和save命令都会执行。另外,因为save命令是由Redis主程序执行的,所以在save命令执行期间,主程序会被阻塞。三种策略优缺点:AOF_FSYNC_NO策略虽然表面上看起来提升了性能,但是会存在每次save命令执行的时候相对长时间阻塞主进程的问题。并且数据的安全性的不到保证,如果Redis服务器突然宕机,那么没有从AOF缓存中保存到硬盘中的数据都会丢失。AOF_FSYNC_ALWAYS策略的安全性的到了最大的保障,理论上最多丢失最后一次写操作,但是由于每个写操作都会阻塞主进程,所以Redis主进程的响应速度受到了很大的影响。AOF_FSYNC_EVERYSEC策略是比较建议的配置,也是Redis的默认配置,相对来说兼顾安全性和性能。重写机制:随着命令不断从AOF缓存中写入到AOF文件中,AOF文件会越来越大,为了解决这个问题,Redis引入了AOF重写机制来压缩AOF文件。AOF文件的压缩和RDB文件的压缩原理不一样,RDB文件的压缩是使用压缩算法将二进制的RDB文件压缩,而AOF文件的压缩主要是去除AOF文件中的无效命令,比如说:同一个key的多次写入只保留最后一个命令已删除、已过期的key的写命令不再保留重写流程:执行bgrewriteaof命令的时候,如果当前有进程正在执行AOF重写,那么直接返回;如果有进程正在执行bgsave,那么等待bgsave执行完毕再执行AOF重写。Redis主进程会fork一个子进程执行AOF重写,开销和RDB重写一样。AOF重写过程中,不影响Redis原有的AOF过程,包括写消息到AOF缓存以及同步AOF缓存中的数据到硬盘。AOF重写过程中,主进程收到的写操作还会将命令写到AOF重写缓冲区,注意和AOF缓冲区区分开。由于AOF重写过程中原AOF文件还在陆续写入数据,所以AOF重写子进程只会拿到fork子进程时的AOF文件进行重写。子进程拿到原AOF文件中的数据写道一个临时的AOF文件中。子进程完成AOF重写后会发消息给主进程,主进程会把AOF重写缓冲区中的数据写道AOF缓冲区,并且用新的AOF文件替换旧的AOF文件。其他细节性说明:Redis对AOF的重要性看得比RDB重,因为RDB的时候如果有进程正在执行AOF,那么直接返回;而AOF的时候如果有进程正在执行RDB,那么等RDb结束再执行AOF。Redis再AOF重写的时候新建一个AOF重写缓冲区的目的是为了保证重写过程中的写命令数据不会丢失。子进程在重写AOF文件的时候,每次写硬盘的数据量由配置决定,不能太大,否则会导致硬盘阻塞(默认32MB)。AOF重写的整个过程有三个部分会阻塞进程:主进程fork子进程的时候主进程把AOF重写缓冲区中的数据写到AOF缓冲区的时候使用新的AOF文件替换掉旧的AOF文件的时候总结RDB持久化基于内存快照存储二进制文件,AOF持久化基于写命令存储文本文件。RDB文件采用了压缩算法,比较小;AOF文件随着命令的叠加会越来越大,Redis提供了AOF重写来压缩AOF文件。恢复RDB文件的速度比AOF文件快很多。RDB持久化方式实时性不好,所以AOF持久化更主流。合理的使用AOF的同步策略,理论上不会丢失大量的数据。Redis重启时加载持久化文件的顺序Redis重启的时候优先加载AOF文件,如果AOF文件不存在再去加载RDB文件。如果AOF文件和RDB文件都不存在,那么直接启动。不论加载AOF文件还是RDB文件,只要发生错误都会打印错误信息,并且启动失败。 编程 - 数据库 Redis 笔记
Redis安装(PHPredis服务+windows的redis环境) 2019-07-17 08:37:28 - 2025-08-18 00:12:03 無慕 - 953 - 28秒 - 2.42K 为PHP安装Redis服务使用phpinfo();查看PHP的版本:去下面的两个网站下载对应版本的压缩包并解压(注意:必须下载 nts 版本)https://windows.php.net/downloads/pecl/releases/igbinary/https://windows.php.net/downloads/pecl/releases/redis/复制两个文件中的如下四个文件到php环境中的ext文件夹中(F:\phpstudy\PHPTutorial\php\php-7.0.12-nts\ext)打开Apache的配置文件 php.ini,复制下面的两行代码到php.ini 文件中,并重启环境extension=php_igbinary.dll extension=php_redis.dll重新使用 phpinfo() 函数 查看php相关信息,出现下图才是安装成功,如果失败请查看下载的对应压缩包的版本是否正确给windows安装redis环境(win10)去下面的网站下载对应的压缩包并解压:https://github.com/MicrosoftArchive/redis/releases/直接解压,并且cmd到解压目录下,运行文件夹中的redis-server.exe,出现下图即为安装成功:要想在PHP中使用redis这个窗口是不能关的,否则redis将无法使用。当然如果一直开着会很麻烦,所以我们设置一下开机自启,让他在系统中一直启动着。用cmd打开解压目录,运行以下代码:redis-server --service-install redis.windows-service.conf --loglevel verbose设置开机自动启动,打开cmd窗口并输入:services.msc,找到redis 服务点击启动即可相关报错如果命令失败是找不到redis服务的1067错误:原因1:可能是因为他需要在logs目录下生成日志文件,而执行命令时权限不够没有生成,所以只需要手动创建一个logs目录即可。原因2:肯能是因为redis的启动窗口未关闭造成的 编程 - 后端 PHP Redis 数据库 教程