Swoole中websocket Server的使用? 2021-09-24 14:02:18 - 2025-07-14 00:06:04 無慕 - 1.70K - 20.52分钟 - 1.66K 首先需要在系统中安装swoole服务!PHP的ws_server.php文件中的代码://创建WebSocket Server对象,监听0.0.0.0:9502端口 $ws = new Swoole\WebSocket\Server('0.0.0.0', 9502); //监听WebSocket连接打开事件 $ws->on('Open', function ($ws, $request) { $ws->push($request->fd, "hello, welcome\n"); }); //监听WebSocket消息事件 $ws->on('Message', function ($ws, $frame) { echo "Message: {$frame->data}\n"; $ws->push($frame->fd, "server: {$frame->data}"); }); //监听WebSocket连接关闭事件 $ws->on('Close', function ($ws, $fd) { echo "client-{$fd} is closed\n"; }); $ws->start();客户端向服务器端发送信息时,服务器端触发 onMessage 事件回调服务器端可以调用 $server->push() 向某个客户端(使用 $fd 标识符)发送消息在Linux中运行程序php ws_server.php可以使用 Chrome 浏览器进行测试,JS 代码为:var wsServer = 'ws://127.0.0.1:9502'; var websocket = new WebSocket(wsServer); websocket.onopen = function (evt) { console.log("Connected to WebSocket server."); }; websocket.onclose = function (evt) { console.log("Disconnected"); }; websocket.onmessage = function (evt) { console.log('Retrieved data from server: ' + evt.data); }; websocket.onerror = function (evt, e) { console.log('Error occured: ' + evt.data); };其他相关说明请查看:Swoole官网 编程 - 后端 插件 PHP
VSCode插件推荐 2020-08-17 08:46:00 - 2025-07-14 00:06:04 無慕 - 117 - 10秒 - 2.04K 插件篇GitLens理由:可以跟踪每行代码的git提交修改记录。而且可以追溯这个文件所有提交记录Chinese (Simplified) Language中文简体语言包koroFileHeader用于生成文件头部注释和函数注释的插件使用篇 编程 - 编程软件 VSCode 插件
谷歌插件推荐 2019-08-17 08:55:28 - 2025-07-14 00:06:03 無慕 - 275 - 36秒 - 2.09K 插件篇FeHelper(前端助手)内置很多实用工具,例如:josn美化、时间戳转化工具、思维导图、网页性能检测、二维码生成/解码、代码压缩工具、MArkdown工具、页面取色工具、简易postman…………Charset可以改变页面的编码格式。广告净化器可以根据具体网站和对应的元素进行屏蔽,可以选择任意元素进行屏蔽,不仅限于广告。喵喵折可以查看各大网商的历史价格变化曲线,自动生成在商品详情页上,鼠标移动上去自动显示。Video speed buttons可以通过s(减小)和d(增加)页面视频的播放速度,实测后发现包括一些学习视频,不能快进的也可以! 编程 - 编程软件 插件 浏览器
PhpStorm插件推荐 2019-08-17 08:39:28 - 2025-07-14 00:06:03 無慕 - 184 - 1.03分钟 - 1.94K 插件篇GitToolBox理由:可以跟踪每行代码的git提交修改记录。Translation最好用的翻译软件,选中代码Ctrl+shift+Y翻译代码,Ctrl+shift+O打开翻译器。使用篇//todo的用途由于某些原因,导致部分代码没有写,但又怕忘记,可以以//todo为开始写注释,后期想要查找时,可以使用快捷键alt+6查看项目中那些文件使用了//todo。 编程 - 编程软件 插件 PhpStorm
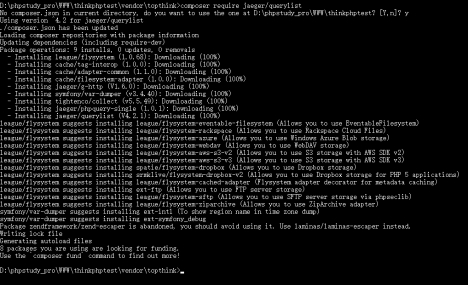
PHPQueryList数据爬取 2019-05-17 22:39:12 - 2025-07-14 00:06:03 無慕 - 9.48K - 0秒 - 1.73K 说明QueryList是一套用于内容采集的PHP工具,它使用更加现代化的开发思想,语法简洁、优雅,可扩展性强。相比传统的使用晦涩的正则表达式来做采集,QueryList使用了更加强大而优雅的CSS选择器来做采集,大大降低了PHP做采集的门槛,同时也让采集代码易读易维护。QueryList是直接获取的页面上的元素内容,而不是直接获取api中的内容。使用文档安装网址:https://querylist.cc/,新版环境要求php>=7.1composer安装命令:composer require jaeger/querylis如果上面的composer命令太慢,请使用国内镜像:composer config -g repo.packagist composer https://mirrors.aliyun.com/composer/使用说明:当时使用时是在tp5中测试使用的,所以下面的内容都是基于tp5进行举例的。设置采集地址$ql=QueryList::get($src);获取单个数据$data=$ql->find('div')->attr("id");//获取页面上一个div的id值QueryList有个find()方法,用于采集单个元素,它通过jQuery选择器选择DOM元素,用法同jQuery的find()方法。获取属性值$ql=QueryList::get('https://www.iqshw.com/'); //获取第一张图片的链接地址,下面四种方法完全等价 $data[]=$ql->find('div')->attr('src'); $data[]=$ql->find('div')->src; $data[]=$ql->find('div:eq(0)')->src;//等推获取第n张:img:eq(n-1) $data[]=$ql->find('div')->eq(0)->src;//等推获取第n张:eq(n-1) //获取其他属性值 $data[]=$ql->find('div')->alt; //获取其它自定义属性值,只能获取一种 //获取所有属性值 $data[]=$ql->find('div')->attr("*"); //获取元素下的HTML内容 $data[]=$ql->find('#id')->html(); $data[]=$ql->find('#id .class')->html(); //获取其它自定义属性值,只能获取一种 //获取元素下的纯文本内容 $data[]=$ql->find('.class')->text();获取多条数据获取多个元素的单个属性值(QueryList中凡是涉及到集合的地方返回的都是Collection集合对象,这个对象有个all()方法,用于把当前对象转成数组,所以你会发现下面很多写法都是$data->all() )$ql=QueryList::get('https://www.iqshw.com/'); //获取所有图片的src属性值 $data[]=$ql->find('img')->map(function ($item){ return $item->src; })->all(); //等价与下面这句话 $data[]=$ql->find('img')->attrs('src')->all(); //获取元素中所有的html内容和text内容 $data[]=$ql->find('#id')->htmls()->all(); $data[]=$ql->find('.class')->texts()->all();列表采集列表采集才是QueryList的核心功能,这里主要涉及到两个函数的用法:rules()和range()$rules = [ '规则名1' => ['选择器1','元素属性'], '规则名2' => ['选择器2','元素属性'], // ... ]; //代码示例: $ql=QueryList::get('https://www.cnblogs.com/yulongcode/'); //定义采集规则 $rules=[ //采集标题 'title'=>['.postTitle2','text'], //采集内容 'text'=>['.c_b_p_desc','text'], //采集时间 'time'=>['.dayTitle','text'] ]; $data=$ql->rules($rules)->query()->getData()->all(); //等同于上面 $data=$ql->rules($rules)->queryData();用range()函数来配合rules()进行循环采集列表内容,range()函数的作用是选择一个元素作为多个数据之间的“切片”。$ql=QueryList::get('https://www.cnblogs.com/yulongcode/'); //定义采集规则 $rules=[ //采集标题 'title'=>['.postTitle2','text'], //采集内容 'text'=>['.c_b_p_desc','text'], //采集时间 'time'=>['.dayTitle','text'] ]; $range='.day';//切片选择器 $data=$ql->rules($rules)->range($range)->query()->getData()->all();内容过滤利用remove()来过滤不需要的内容:$ql = QueryList::get('https://www.cnblogs.com/yulongcode/'); //移除选中html中的a标签 $data = $ql->find('.c_b_p_desc:eq(0)')->remove('a')->html(); //只保留a标签中的html内容 $data = $ql->find('.day:eq(0)')->find('a')->remove()->html();列表采集时过滤不需要的元素,使用规则:$rules = [ '规则名1' => ['选择器1','元素属性','内容过滤选择器'], '规则名2' => ['选择器2','元素属性','内容过滤选择器'], // ... ];内容过滤选择器参数不光可以定义要移除的内容还可以定义要保留的内容,多个值之间用空格隔开, 有如下2条规则:内容移除规则:选择器名前面添加减号(-),表示移除该标签以及标签内容。内容保留规则:选择器名前面没有减号(-)(此时选择器只能为HTML标签名,不支持其他选择器), 当要采集的[元素属性] 值为text时表示需要保留的HTML标签以及内容,为html时表示要过滤掉的 HTML标签但保留内容。$ql = QueryList::get('https://www.cnblogs.com/yulongcode/'); //定义采集规则 $rules = [ //采集标题 'title' => ['.postTitle2', 'text'], //采集内容 'text' => ['.c_b_p_desc', 'html','-a'], //采集时间 'time' => ['.dayTitle', 'text'] ]; $range = '.day';//切片选择器 $data = $ql->rules($rules)->range($range)->query()->getData()->all();数据处理获取到数据后进行二次处理:$ql = QueryList::get('https://www.cnblogs.com/yulongcode/'); //定义采集规则 $rules = [ //采集标题 'title' => ['.postTitle2', 'text'], //采集内容 'text' => ['.c_b_p_desc', 'html'], //采集时间 'time' => ['.dayTitle', 'text'] ]; $range = '.day';//切片选择器 $data = $ql->rules($rules)->range($range)->query()->getData(function($item){ $qls = QueryList::html($item['text']); $qls->find('a')->remove(); $item['content'] = $qls->find('')->html(); return $item; })->all();乱码处理$ql = QueryList::get('https://www.iqshw.com/'); //定义采集规则 $rules = [ //采集标题 'title' => ['a', 'text'], ]; $range = 'li';//切片选择器 //乱码处理,设置输出编码 $data = $ql->rules($rules)->range($range) ->encoding('UTF-8','GB2312') ->query()->getData()->all(); //如果设置输出参数无法解决乱码,那就使用removeHead()方法移除html头部 $data = $ql->rules($rules)->range($range) ->removeHead()->query()->getData()->all(); //或者 $data = $ql->rules($rules)->range($range) ->encoding('UTF-8','GB2312') ->removeHead()->query()->getData()->all(); //手动转码 $html=$text=iconv("GB2312","UTF-8",file_get_contents('https://www.iqshw.com/')); $data = QueryList::html($html)->rules([ 'title' => ['.news-comm-wrap a ', 'text'], ])->range($range)->query()->getData()->all();简化数据$ql = QueryList::get('https://www.cnblogs.com/yulongcode/'); //定义采集规则 $rules = [ //采集标题 'title' => ['.postTitle2', 'text'], ]; $range = '.day';//切片选择器 //使用flatten()方法将多维集合转为一维的 $data = $ql->rules($rules)->range($range)->query()->getData()->flatten()->all();截取数据$ql = QueryList::get('https://www.cnblogs.com/yulongcode/'); //定义采集规则 $rules = [ //采集标题 'title' => ['.postTitle2', 'text'], ]; $range = '.day';//切片选择器 //take()方法返回给定数量项目的新集合,对最初的采集结果data进行处理: $data = $ql->rules($rules)->range($range)->query()->getData()->take(2)->all();反转数据顺序$ql = QueryList::get('https://www.cnblogs.com/yulongcode/'); //定义采集规则 $rules = [ //采集标题 'title' => ['.postTitle2', 'text'], ]; $range = '.day';//切片选择器 //使用reverse()来倒转集合中的项目 $data = $ql->rules($rules)->range($range)->query()->getData()->reverse()->all();过滤数据$ql = QueryList::get('https://www.cnblogs.com/yulongcode/'); //定义采集规则 $rules = [ //采集标题 'title' => ['.postTitle2', 'text'], ]; $range = '.day';//切片选择器 //filter()方法用于按条件过滤数据,只保留满足条件的数据。 //只能过滤,不能修改添加原数据,如果需要修改添加则用getData $data = $ql->rules($rules)->range($range)->query()->getData() ->filter(function ($item){ return $item['title']!='PHP使用引用实现无限极分类'; })->all();遍历数据$ql = QueryList::get('https://www.cnblogs.com/yulongcode/'); //定义采集规则 $rules = [ //采集标题 'title' => ['.postTitle2', 'text'], ]; $range = '.day';//切片选择器 //map() 方法遍历集合并将每一个值传入给定的回调。 //该回调可以任意修改项目并返回,从而形成新的被修改过项目的集合。 $data = $ql->rules($rules)->range($range)->query()->getData() ->map(function ($item){ $item['time']=time(); return $item; })->all();其他操作attr()方法除了获取DOM元素的值外,还有第二个参数,用于设置元素属性值text()方法是获取元素的纯文本内容,加参数表示设置元素内容html()方法是获取元素的HTML内容,加参数表示设置元素HTML内容以上三个用法基本和jQuery相同,添加完后再获取,才会出现在获取的数据中。append()追加元素replaceWith()替换元素removeAttr()移除元素属性parent()用户获取当前元素的父级元素next()和prev()用于获取当前元素临近的下一个元素和上一个元素更多使用说明请查看使用文档。 编程 - 数据抓取 PHP jQuery 插件